


Moveable Doc Codecs (PDFs) are a cornerstone of contemporary doc sharing. They provide a constant and dependable method to current info, whatever the gadget or working system used.
Nonetheless, the very nature of PDFs – their mounted format and image-based textual content – could make extracting information a tedious and time-consuming job. That is the place PDF information extraction is available in.
This text explores varied strategies for extracting information from PDFs in 2024. Stick to us as we talk about the challenges concerned, and introduce you to AlgoDocs, a strong and user-friendly resolution for automated PDF information extraction.

Complexities in PDF information extraction
Whereas PDFs supply quite a few benefits, extracting information from them presents a number of challenges that may considerably decelerate workflows and introduce errors when coping with giant volumes of PDFs.
These challenges embody PDFs’ mounted format, which differs from the dynamic nature of spreadsheets or databases, making it troublesome to isolate and extract particular information factors. Moreover, textual content inside PDFs is commonly embedded as pictures relatively than searchable textual content, necessitating the usage of Optical Character Recognition (OCR) expertise to transform pictures into editable textual content.
PDFs can have various layouts, fonts, and tables, making it difficult to develop a standardized strategy to information extraction. Extracting information from tables or varieties inside PDFs requires further parsing and logic to deal with complicated information constructions, together with the construction and hierarchy of the knowledge.

Strategies for Knowledge Extraction
Outdated Methodology
Essentially the most primary strategy to PDF information extraction is guide copying and pasting. This entails opening the PDF, choosing the specified textual content, and pasting it into one other software like Excel or a phrase processor. Whereas this methodology works for easy circumstances, it turns into extremely time-consuming and error-prone when coping with a major variety of recordsdata.
Automated PDF information extraction – 2024 Strategies
Luckily, technological developments have led to the event of automated PDF information extraction instruments. These instruments make use of varied strategies, together with:
- Optical Character Recognition (OCR): OCR expertise converts scanned pictures of textual content inside PDFs into editable and searchable textual content. This permits the extraction device to determine and course of the info.
- Pure Language Processing (NLP): NLP strategies can be utilized to know the context and construction of the info inside the PDF. This helps the device differentiate between related info and irrelevant textual content.
- Machine Studying (ML): ML algorithms will be educated on giant datasets of PDFs to determine patterns and enhance the accuracy of information extraction over time.
Which Methodology Works Greatest for You?
Figuring out probably the most appropriate methodology for information extraction largely depends upon your degree of experience and the complexity of your recordsdata. Handbook extraction could suffice initially for freshmen or startups with comparatively easy extraction wants and a restricted quantity of recordsdata. This methodology entails manually copying and pasting information from PDFs, which will be time-consuming however manageable for smaller duties.
Nonetheless, transitioning to automated information extraction instruments like AlgoDocs may very well be extremely useful if your small business calls for sooner and extra correct outcomes. With its intuitive interface and strong options, AlgoDocs simplifies the extraction course of, saving you invaluable time and minimizing errors. Plus, it affords a eternally free plan together with subscription choices tailor-made to accommodate companies of all sizes, making it accessible and cost-effective.
Fast Tip: When contemplating whether or not to change to automated information extraction, begin by evaluating the quantity and complexity of your recordsdata. If guide extraction turns into too cumbersome or vulnerable to errors, it might be time to discover automated options like AlgoDocs. Remember that even with automated instruments, it is important to usually assessment and optimize your extraction processes to make sure effectivity and accuracy.
AlgoDocs PDF Extract API
AlgoDocs affords a strong API for builders in search of to combine PDF information extraction functionalities into their purposes. The API permits programmatic entry to the platform’s core functionalities, enabling builders to construct customized workflows and combine information extraction seamlessly into their present methods.
Key options of AlgoDocs PDF Extract
AlgoDocs PDF Extract is a strong and user-friendly platform particularly designed for automated PDF information extraction, with a free plan accessible that lets you course of as much as 50 pages per 30 days. Listed here are a few of its key options:
Cloud-based:
AlgoDocs operates on the cloud, eliminating the necessity for complicated installations. Accessible from any gadget with web connectivity, it seamlessly integrates into your workflow.
Unparalleled Accuracy:
Using superior applied sciences like OCR, NLP, and machine studying, AlgoDocs ensures exact information extraction. Your information is extracted with utmost constancy.
Versatile Knowledge Mapping:
Customise your information extraction course of with AlgoDocs’ versatile information mapping function. Simply map extracted information to particular fields in Excel, CSV, or JSON codecs.
A number of File Uploads:
AlgoDocs helps batch processing, permitting you to add and course of a number of PDFs concurrently. This environment friendly function saves time and assets.
Safe Knowledge Dealing with:
AlgoDocs prioritizes information safety. All uploaded paperwork and extracted information are encrypted, offering complete safety all through the extraction course of.
The way to convert PDF to Excel with AlgoDocs (Step-by-Step Information)
This is an in depth information on changing PDF information to Excel utilizing AlgoDocs PDF Extract:
Step 1: Log in to your AlgoDocs account.
Step 2: From the Dashboard, click on on the File Supervisor tab  .
.
Step 3: Proper-click on the root ![]() , and a drop-down menu will pop up displaying accessible choices comparable to Convert PDF/Picture to Editable Information.
, and a drop-down menu will pop up displaying accessible choices comparable to Convert PDF/Picture to Editable Information. 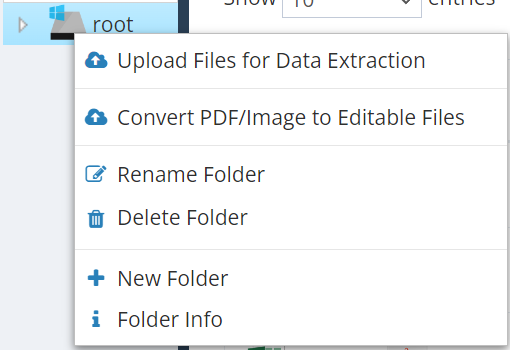 .
.
Step 4: Click on on Convert PDF/Picture to Editable Information .
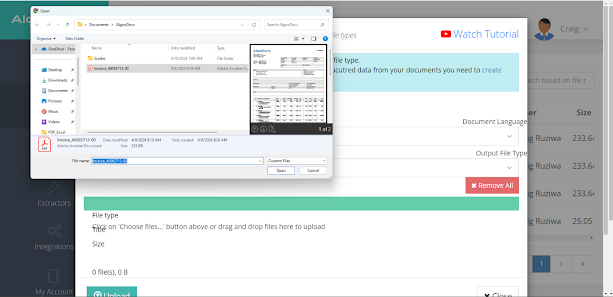
Step 5: Click on on the blue button labeled + Select recordsdata ![]() , which lets you add your file. As soon as you choose the PDF/Picture, will probably be uploaded.
, which lets you add your file. As soon as you choose the PDF/Picture, will probably be uploaded.
Step 6: Subsequent, choose the Doc language ![]() from the language drop-down menu. Be happy to pick multiple language, in case your file has multilanguage textual content.
from the language drop-down menu. Be happy to pick multiple language, in case your file has multilanguage textual content.
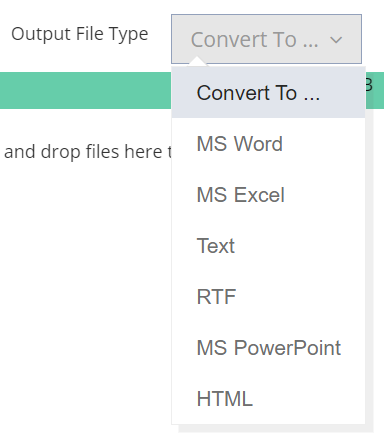
Step 7: Choose the specified output file format, from the Output file sort, drop-down menu. On this demonstration, we are going to choose Excel. The opposite output sorts embody MS Phrase, PowerPoint, Textual content, RTF and HTML.
Step 8: The following step is to add recordsdata by clicking on Add  button, and the magic will begin (AlgoDocs will course of the file very quickly).
button, and the magic will begin (AlgoDocs will course of the file very quickly).
Step 9: As soon as the conversion is full, the uploaded doc will disappear from the pop-up window, and you may click on on the Shut  button situated on the backside proper nook to return to the File Supervisor window.
button situated on the backside proper nook to return to the File Supervisor window.
Step 10: Walla, an icon to entry and obtain the transformed Excel file is proven to the left of the file sort icon.
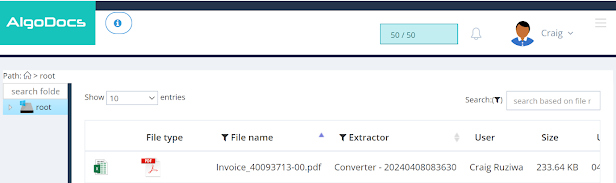
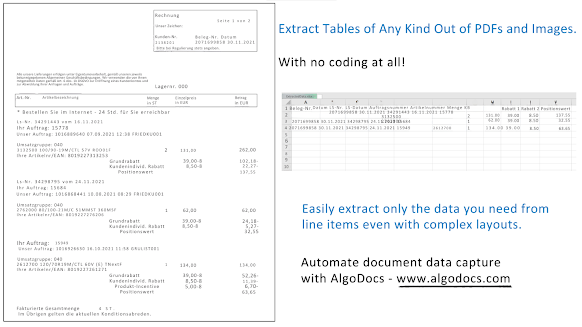
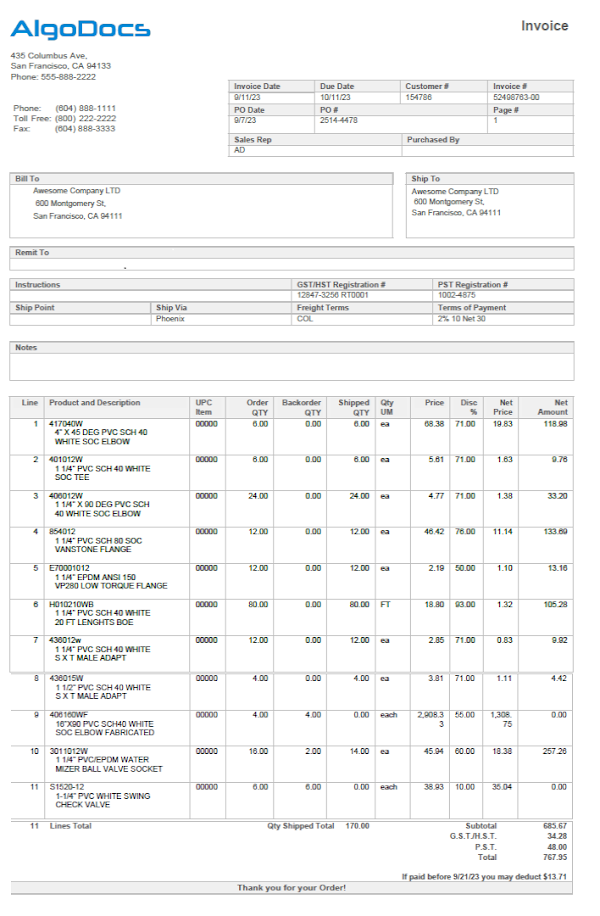
Step 11: If you click on on the Excel icon ![]() the Excel file might be downloaded. Determine 1. exhibits a pattern PDF used for this demonstration and Determine 2. Exhibits the output Excel file.
the Excel file might be downloaded. Determine 1. exhibits a pattern PDF used for this demonstration and Determine 2. Exhibits the output Excel file.
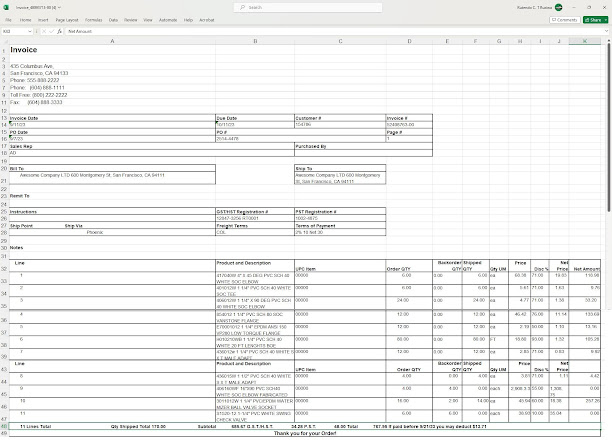
Observe: The free trial account lets you course of 50 pages/month. Confer with AlgoDocs pricing plans for particulars on inexpensive paid subscription choices.
AlgoDocs Accuracy
At AlgoDocs, precision in information extraction is paramount. We obtain this by using a mix of superior Optical Character Recognition (OCR), Pure Language Processing (NLP), and machine studying applied sciences.
Nonetheless, it is essential to acknowledge that the accuracy of conventional OCR instruments could also be vulnerable to numerous components. These components embody the standard of the PDF itself, the place blurry or low-resolution PDFs can diminish OCR accuracy.
Extremely intricate doc layouts that includes complicated tables or nested constructions would possibly necessitate additional configuration to optimize extraction outcomes. Furthermore, information formatting or presentation inconsistencies inside the PDFs can even impression the extraction course of.
Professionals and Cons of utilizing AlgoDocs
| Professionals | Cons |
| Consumer-friendly interface | Slight studying curve for customers new to information extraction instruments |
| Correct information extraction with OCR, NLP, and ML | Free trial accounts could have processing quantity limitations |
| Helps varied output codecs | |
| Environment friendly dealing with of enormous PDF volumes | |
| Sturdy information safety measures | |
| Aggressive pricing plans for all enterprise sizes |
What’s OCR, and the way does AlgoDocs use OCR expertise to finish the conversion course of precisely?
Optical Character Recognition (OCR) is a transformative expertise that allows computer systems to discern textual content inside pictures. AlgoDocs capitalizes on state-of-the-art OCR engines to seamlessly convert scanned textual content pictures inside PDFs into editable and searchable codecs. This performance is pivotal for making certain the utmost accuracy in information extraction, because it empowers the platform to acknowledge and interpret the knowledge encapsulated inside the doc adeptly.
This is how AlgoDocs makes use of OCR expertise:
- Picture Preprocessing: AlgoDocs would possibly pre-process the scanned picture earlier than making an attempt textual content recognition to enhance accuracy. This might contain noise discount, sharpening, or skew correction.
- Textual content Recognition: The picture is fed into a complicated OCR engine as soon as pre-processed. The engine analyzes the picture, recognizing particular person characters and patterns. It then compares these patterns to an unlimited database of fonts and symbols to find out the more than likely characters.
- Put up-processing: AlgoDocs would possibly carry out post-processing steps to refine the extracted textual content after textual content recognition.
Closing Ideas
The duty of extracting information from PDFs can typically show tedious. Nonetheless, because of latest technological developments, instruments like AlgoDocs emerge as potent options. Via the combination of Optical Character Recognition (OCR), Pure Language Processing (NLP), and machine studying, AlgoDocs automates this course of, leading to time financial savings and error discount.
Whether or not you are a person or a enterprise grappling with a deluge of PDF paperwork, AlgoDocs affords a streamlined resolution. It facilitates the extraction of invaluable information out of your recordsdata with outstanding effectivity.
Able to attempt AlgoDocs? Join a free trial as we speak and expertise the convenience and effectivity of automated PDF information extraction
Supply hyperlink





